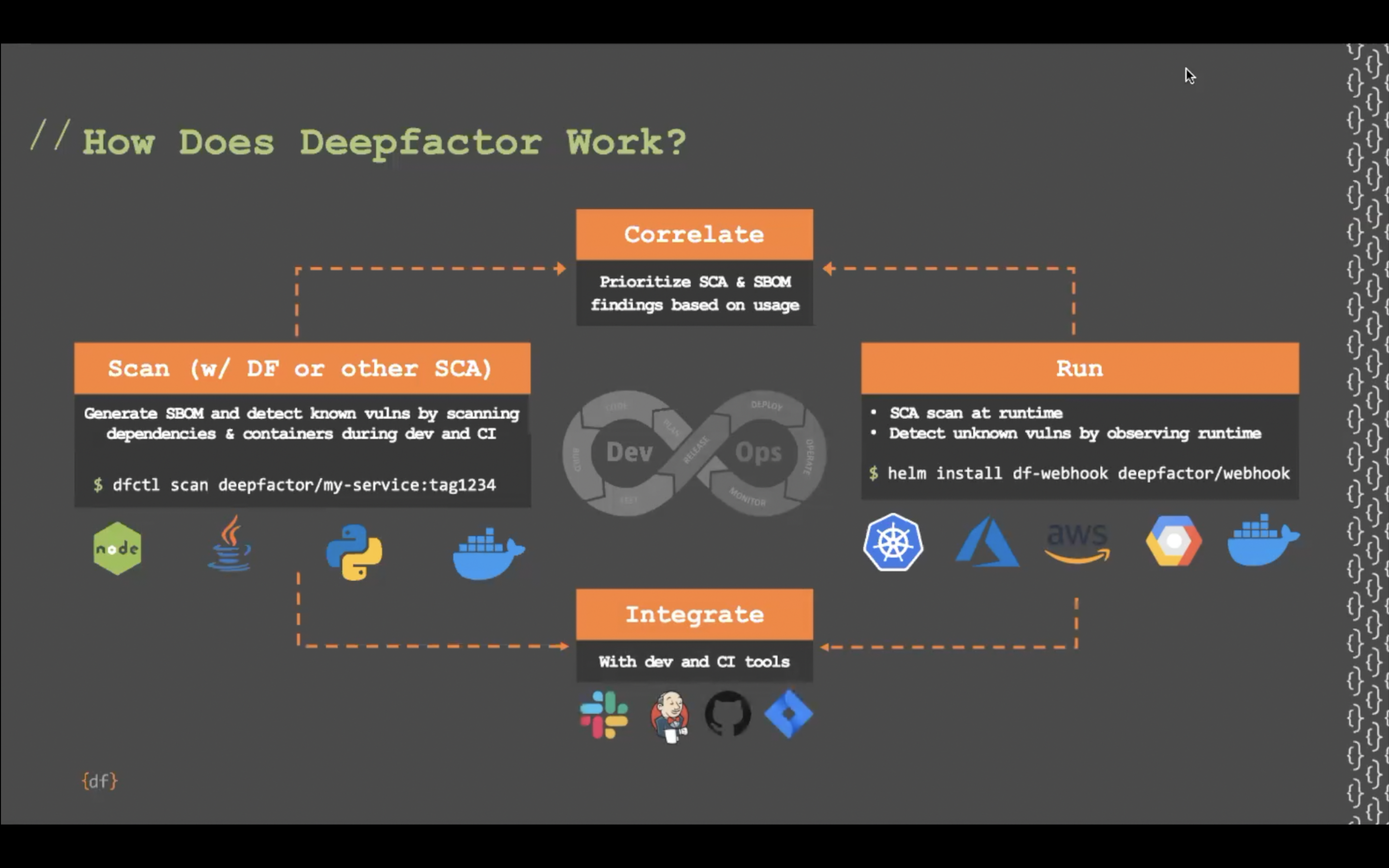

You can run Deepfactor in dev, QA, staging or production environments. As a best practice, we highly encourage customers to incorporate Deepfactor into their dev, QA and staging environments first, so they can catch security issues early during development and testing.
For running in production environments, please review the following considerations:
- Understand performance:
While we take exhaustive measures to ensure that the performance overhead is minimal, the ultimate measure of actual performance overhead depends on the amount of application telemetry events generated by the applications that Deepfactor is observing. We recommend that customers run applications with Deepfactor in dev/staging environments with sufficient load before running them with Deepfactor in production environment so they are aware of the performance overhead and can provision accordingly. In a kubernetes deployment, customers may need to increase the pod CPU and memory limits. The more concurrent active processes being monitored, the more memory Deepfactor will consume. - Understand the support matrix:
The list of supported Operating Systems, languages and limitations are outlined in the following document. Please review and ensure that your deployment uses one of the configurations described in : Deepfactor support matrix - Co-existing with monitoring/APM/other tools in your production environment:
Your application may not work with Deepfactor if LD_PRELOAD is set in the environment. Some performance monitoring tools set LD_PRELOAD. - Configure appropriate TTLs in the on-premise Depfactor portal:
Since applications will be long running, set an appropriately low TTL on your on-premise Deepfactor portal to avoid high disk usage. This can be specified on the on-screen options for OVA/AMI deployments and as a helm override parameter for kubernetes installations. Please consult with your Deepfactor customer success manager for assistance. - Disable Stack Tracing:
Stack tracing is an advanced feature that will help Deepfactor pinpoint the line of code where a vulnerable behavior exists. This is very useful while running Deepfactor in your dev & test environments, and enables the engineering team to quickly resolve the security risk. However, it is a performance intensive operation, and therefore, isn’t recommended for production environments. We recommend turning off stack trace collection in production environments. You can read more about this feature in the following article : Language Specific Agents (LSA) - Disable Usage Tracking:
Deepfactor automatically intercepts class loaded event for java applications and provide the list of classes loaded per java dependency. It’s a great way to prioritize vulnerabilities based on usage of the vulnerable dependency. Since collecting this usage information is a performance intensive task, we do not recommend this mode for production environments. Instead, we recommend customers disable usage tracking while running Deepfactor in production environments. You can read more about this feature in the following article.
Language Specific Agents (LSA) - Disable collection of dependency information and OS package information
Collecting dependency information and OS package information can create a spike in CPU usage at application/pod start that may cause the application to fail to start (or start slowly). Since the dependency information and OS package information generally does not vary between dev/test and production, Deepfactor recommends using the dev/test environment to collect this information (and resulting alerts).To disable collection of dependency event and/or OS package information telemetry and avoid the startup CPU spike, use the following annotation in your helm chart:# # set to false to disable OS package manager queries for vuln. analysis # packageInfoEvents: true # # # set to false to disable dependency checking for vuln. analysis for Java # dependencyCheckInfoEvents: true - Package Query Delay in milliseconds
If collecting dependency information and OS package information is desired for production workloads you can configure a throttle time in milliseconds to eliminate CPU spike during this process.This can be configured using the following annotation in your helm chart:# # set to a positive value to set the package query time delay in milliseonds # packageQueryDelayMS: 250
- Differentiate between non-production and production environment insights:
It’s always a good idea to group your dev/test and prod findings into separate buckets. In order to differentiate between insights seen in non-production environments such as dev/qa/staging and production environments, we recommend the following approaches
i. Use the environment (env) option
dfctl command line utility and the Deepfactor kubernetes admission webhook provide an option (–env or envName) for specifying the environment your application is running in. You can filter based on the environment in the application dashboard screen. You can read more about this option in the following articles
Configure Deepfactor Mutating Webhook
Deepfactor CLI Referenceii. Create a different application for production environment
If you would like greater isolation between findings observed in non-production and production environments, you can choose a different application name (ex. prod-myapp) while running in production environment. In case of the Kubernetes admission webhook, this can achieved by updating the appName option. You can read about this option in the following article.
Configuring application name, component name and component version in K8s webhook