

Whitepaper: SCA 2.0 — A Framework to Prioritize Risk, Reduce False Positives, and Eliminate SCA Alert Fatigue
6 strategies to prioritize runtime alerts.
Download Now >Share:



How to Use Reachability Analysis to Prioritize SCA Findings
Although software composition analysis (SCA) has been around for over 20 years, it continues to remain a tedious and time-consuming exercise for both developers and AppSec teams. Some of the reasons for this are:
- Multiple sources: There are several vulnerability sources including unstructured ones such as GitHub issues, feeds, etc.
- Lack of prioritization: Vulnerabilities are ranked using multiple scores such as CVSS, EPSS, etc. Unfortunately, these scores in isolation do not provide enough clarity.
- Lack of context: The true risk of a vulnerability to your application and business is very difficult to assess as it requires context.
- Lack of full SBOM: Engineering discipline—marking dev dependencies appropriately, generating lock files as part of the build before the scan, etc.— is required to get the full SBOM.
- Phantom dependencies: Dependencies used by your application but are not defined in the package manifest files in your source code. These dependencies are generally already present in the container/host.
- Alert fatigue: Most tools find a large number of vulnerabilities associated with your applications but do not provide a framework for you to prioritize them.
These pain points kept coming up in our conversations with industry leaders/practitioners and customers. In order to solve this challenge and help developers build secure code without being overwhelmed with SCA data, we created the SCA 2.0 framework. You can read about the SCA 2.0 framework in this whitepaper, which presents practical strategies to prioritize SCA findings based on multiple parameters such as runtime usage, runtime reachability, exploit availability, severity, topology, and applicability.
Two Different Approaches to Reachability Analysis
“Reachability” refers to the analysis of determining if a particular vulnerability (vulnerable function/class/dependency) is reachable i.e., that there exists a code path to reach the vulnerability that an attacker can potentially leverage. In this blog, I will go into the details of reachability and the different approaches to determine it. There are two main ways of determining reachability: Static call graph analysis and runtime usage analysis. I will dive deeper into these approaches in the following section.
Static Call Graph Analysis
Static call graph analysis tools generate a graph G=<F,E> where F stands for functions in the code and E refers to an edge or a caller->callee relationship by scanning the static source code. In order to generate this graph, these tools will traverse the codebase and identify the target of each branch (callee function) from within the function’s code. Unfortunately the determination of the callee function is not straightforward or reliable in certain commonly occurring circumstances such as virtual dispatch (the mechanism used by object oriented languages to determine the callee function at runtime), function pointers, and dynamically loaded modules. The static analysis tools try to approximately estimate the callee function in such cases.
Here are some considerations around static call graph analysis:
- Approximations: As mentioned above, static call graph analysis requires approximations to be made in common scenarios such as virtual dispatch, function pointers, and dynamically loaded modules. This results in false positives—the tool determines that a call path is reachable when it is not— and false negatives—the tool determines that a call path is unreachable when it is actually reachable. Users should therefore use reachability analysis only for prioritization and NOT for elimination of vulnerabilities.
- Blindspots: Static call graph analysis requires source code to be available and hence cannot determine reachability within binaries.
- Gaps: Generating static call graphs requires the tool to continuously scan the universe of open source dependencies so it can concatenate the application’s call graph with that of its open source dependencies to get a complete call graph. If the source code of an open source dependency is not available or has not been scanned by the tool, it will result in gaps in the graph.
- Lack of reachability for OS packages: While theoretically, it is possible to use static call graph analysis to detect usage of OS packages, most popular tools employing static call graph analysis techniques do not provide usage of OS packages.
- Lower degree of prioritization: Static call graph analysis will try to determine all theoretical code paths (including dead code) as best as it can while approximating certain areas. Static call graphs, therefore, provide a lower degree of prioritization which may not even be reliable in certain situations.
- Earlier feedback: Static call analysis tools can provide reachability information in the CI pipeline because they determine reachability by scanning code and not observing the runtime behavior.
Runtime Usage Analysis
In this approach, the tool instruments the running application to determine runtime usage of dependencies. Here are some considerations of runtime usage analysis:
- Vantage point: In order to get runtime usage of dependencies, the tool should intercept application behavior at the appropriate vantage point. For example, host agents may not have visibility into the usage of dependencies for certain languages.
- 100% accuracy: Runtime usage analysis intercepts real execution of code paths, providing 100% accuracy without any approximations.
- Test coverage: Runtime usage analysis tools provide higher coverage when more code paths are executed i.e., there is higher test coverage. A strategy to improve coverage is to enable the tool in different environments such as dev, QA, staging, and even production. The tool can then gather usage throughout the SDLC.
- Performance impact: Any instrumentation and interception will result in performance overhead. It is important to find a lightweight interception library that provides enough degree of precision while imposing a small performance footprint.
- Language agnostic: While detection of usage of a particular dependency requires some language specific work, the interception technique can be reused across different languages making it easier to add usage analysis for more languages.
- Runtime context: Runtime analysis tools have another important advantage. Since they observe the running application, they can also capture runtime and deployment context of the application such as internet accessibility, cloud provider, listening ports, etc., which can be used for further analysis and prioritization.
How to Use Reachability for Prioritization
When reviewing these two approaches it’s important to understand that reachability should be used as a measure for prioritization and NOT for ignoring vulnerabilities since both static and runtime reachability analysis have blind spots. In other words:
- If a tool determines a vulnerable resource is reachable, please prioritize upgrading it.
- If a tool determines that a vulnerable resource is not reachable, please do NOT ignore it as it may actually be reachable and your tool was not able to detect its usage.
Given that reachability is a prioritization metric, runtime reachability analysis will give developers a much higher degree of prioritization compared to static call graph analysis. It will also provide the list of resources that are definitely used in the normal course of the application rather than all theoretical code paths that may also contain dead code. Static call graphs are marred by the original problems that have existed with traditional SCA tools such as too much noise and lack of visibility into the runtime state or deployment context of the application.
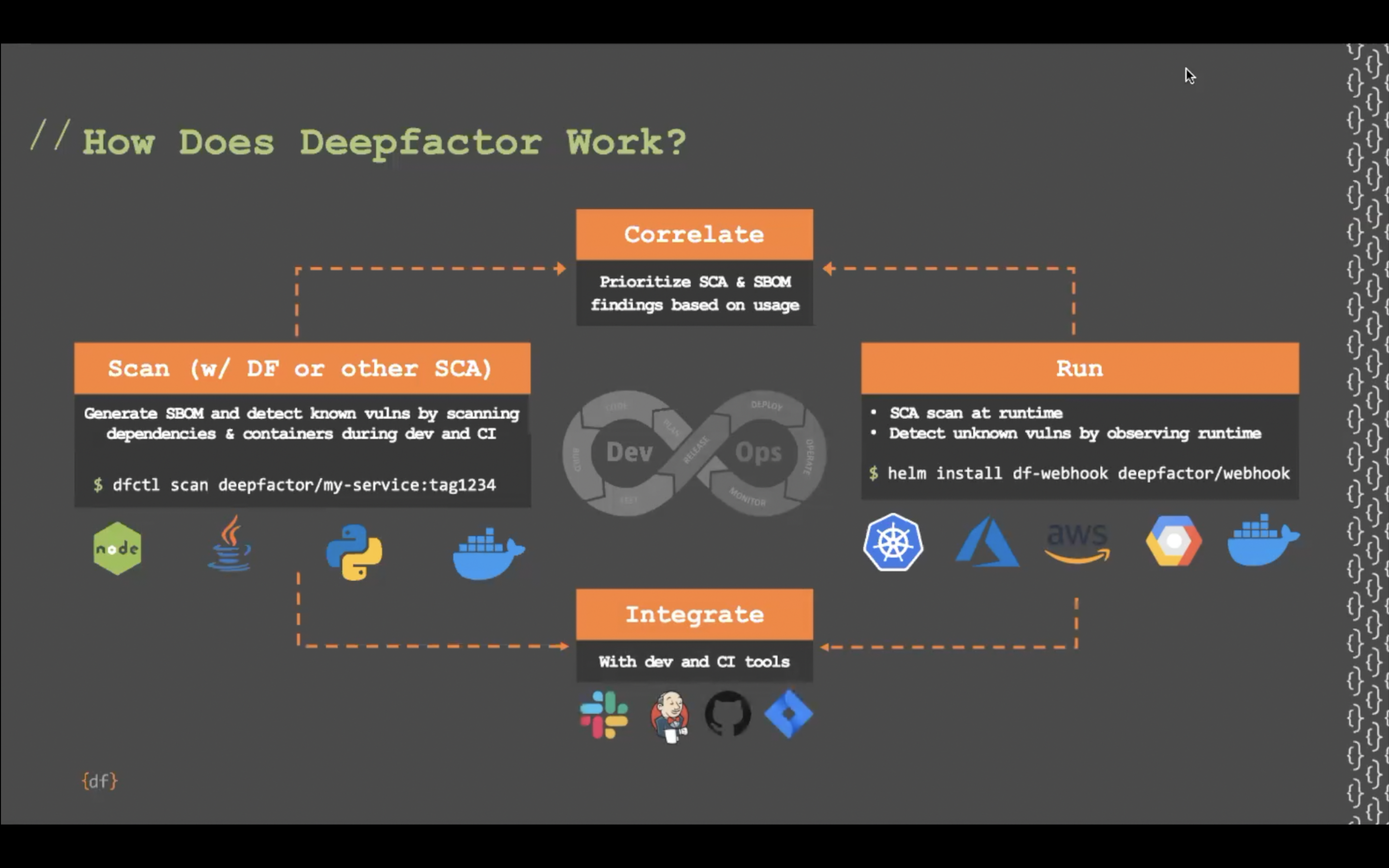
Reachability Analysis with Deepfactor’s ‘Static + Runtime SCA’
At Deepfactor, we have been laser focused on getting runtime usage analysis right and have solved the hard challenges associated with runtime instrumentation. Highlights of Deepfactor’s innovative approach to runtime usage analysis—‘static + runtime SCA’—include:
- Lightweight user space instrumentation: In order to get runtime usage of dependencies, the interception hook should be closer to the application and not to the host. At Deepfactor, we don’t use any host agent or eBPF but inject a lightweight library into the application/container, enabling us to detect usage of dependencies for a myriad of programming languages.
- Low performance overhead: Deepfactor’s interception library has a very small CPU and memory footprint ensuring that users can run their applications with Deepfactor in dev, QA, stage and even production environments..
- Hybrid SCA approach: Deepfactor scans the source code/container image and observes the running application. This hybrid approach gives much higher visibility than only static or only runtime tools, and results in higher SBOM detection coverage (Deepfactor can detect dependencies from manifest files, installed packages, and even phantom dependencies based on usage of dependencies present on the host) while prioritizing the findings based on runtime usage analysis
This table presents a comprehensive comparison between the different SCA approaches:
| Static w/ Call Graph | Runtime Only | Deepfactor’s hybrid approach to reachability (static + runtime) | |
| Detection approach | Manifest file or source code or both | Executed code | Manifest file + source code for greater coverage |
| Detection coverage | Depending upon on the approach (manifest or source code scan) | Depends upon runtime execution. | Direct, transitive dependencies and OS packages |
| Detection time | Early since code/image is scanned in the CI pipeline | Late as the code/image has to be deployed before the tool can analyze | Early since code/image is scanned in the CI pipeline |
| Reachability within application dependencies (jar, node modules, pip modules etc) | Yes with exceptions noted below | Yes | Yes |
| Reachability analysis blindspots | Dynamically loaded resources such as reflection in Java result in false negatives. Lack of visibility into OSS components whose source is unavailable/not scanned. Lack of visibility into usage of OS packages |
Depends upon the code executed at runtime. | Depends upon the code executed at runtime. Mitigated by running your applications with Deepfactor in multiple environments for long durations for greater coverage. Resources that are still unused should be deprioritized as lower risk. |
| Reachability within OS packages for container scans | No | Yes | Yes |
| Noise in reachability analysis | High since static call graphs will use all theoretical paths to determine reachability including old or dead code no longer used in your app | Low as runtime analysis will detect the paths that are definitely executed at runtime | Low as runtime analysis will detect the paths that are definitely executed at runtime |
| Prioritization using exploit availability/maturity | Possible | Possible | Yes. Deepfactor pulls exploit info from multiple sources, pulls PoC information from GitHub and exploited incidents from CISA |
| Prioritization based on internet accessibility | Not possible | Possible | Possible |
| Detection of dead/unused code | Partial (theoretically unreachable code only, not unused/dead code) | Yes | Yes. Deepfactor can highlight the dependencies and OS packages in containers that your application hasn’t used at runtime and your developers can consider trimming them down |
| Detection of unknown vulnerabilities not in CVE databases | Not possible | Possible | Yes. Deepfactor observes application processes for insecure file/network/memory behaviors and detects 11 categories of malicious behaviors that may not be a known CVE today. |
| Scanning of containers that are deployed but not built in the CI pipeline | Not possible | Possible | Yes. In Kubernetes environments, Deepfactor’s scan pod can automatically scan containers as pods are started. |
| Search for vulnerabilities in running environments | Not possible | Possible | Yes. Deepfactor allows you to search whether an application running in any of your environments contains vulnerable OSS deps or packages that contain certain vulnerabilities. This helps assess risk posture to a specific CVE/component. |
| Admission control (Prevent a container from starting up if it has a certain class of vulnerabilities or licenses) | Not possible | Possible | Possible |
Frequently Asked Questions
1. What are the main challenges developers and AppSec teams face with traditional Software Composition Analysis (SCA), and how does the SCA 2.0 framework address these challenges?
Answer: Traditional SCA poses various challenges, including multiple vulnerability sources, lack of prioritization clarity, absence of context, incomplete SBOMs, phantom dependencies, and alert fatigue. The SCA 2.0 framework introduces practical strategies for prioritizing SCA findings based on parameters like runtime usage, reachability, exploit availability, severity, topology, and applicability, aiming to streamline vulnerability management processes and empower developers to build secure code efficiently.
2. What are the two primary approaches to reachability analysis, and how do they differ in determining vulnerability reachability?
Answer: Reachability analysis involves determining if a vulnerability is reachable within an application, crucial for prioritizing vulnerability remediation. The two main approaches are static call graph analysis and runtime usage analysis. Static call graph analysis scans static source code to approximate reachable code paths, while runtime usage analysis instruments the running application, offering more accurate results with 100% accuracy.
3. How should reachability analysis be utilized for vulnerability prioritization, and what are the limitations of solely relying on reachability analysis?
Answer: Reachability analysis should be used as a prioritization metric rather than for ignoring vulnerabilities entirely. If a vulnerable resource is deemed reachable, it should be prioritized for upgrading. Conversely, if a vulnerable resource is considered unreachable, it shouldn’t be ignored, as it might still be reachable under certain conditions. While runtime reachability analysis offers higher prioritization accuracy compared to static call graph analysis, both approaches have blind spots and should be used alongside other vulnerability assessment methods.
4. What distinguishes Deepfactor’s ‘Static + Runtime SCA’ approach in addressing reachability analysis challenges, and what are its key features?
Answer: Deepfactor’s ‘Static + Runtime SCA’ approach combines static code scanning with runtime usage analysis to enhance vulnerability management. This approach utilizes lightweight user space instrumentation for runtime usage analysis, resulting in minimal performance overhead. By scanning both source code and observing running applications, Deepfactor offers a hybrid SCA approach that detects dependencies comprehensively while prioritizing findings based on runtime usage analysis, thus improving vulnerability assessment accuracy and coverage.

Free Trial Signup
The Deepfactor trial includes the full functionality of the platform, hosted in a multi-tenant environment.
Sign Up Today! >