
Whitepaper: SCA 2.0 — A Framework to Prioritize Risk, Reduce False Positives, and Eliminate SCA Alert Fatigue
6 strategies to prioritize runtime alerts.
Download Now >Share:



By now, you have likely heard about the latest OpenSSH security issue (dubbed regreSSHion, since all good bugs require a catchy name). And as usual, we’re seeing many blog posts that just summarize and outline the research done (which, by the way, was amazing), without offering any substantially new advice or thoughts. Frequently, these blogs have nothing more to say than “patch, and if you can’t patch, here’s the workaround”. That’s not insightful. I’m going to take a different angle here; I’m going to suggest that we’re focusing on the wrong thing to begin with and that, while patching and applying workarounds is critically important, the advice we continually see doesn’t improve the ecosystem’s approach to application security over time.
I wrote up my thoughts on the previous OpenSSH issue—xz backdoor— a few months ago. At the time, I illustrated how distribution maintainers had exacerbated the core problem by choosing to include way too many dependencies while linking in “features” into OpenSSH. I showed that some distributions were better than others, and some were just really, really bad.
I think that, from an AppSec context, the danger posed by regreSSHion is also exacerbated by the same sort of thought process (linking in and including too much “stuff” within reach of the application). Except this time, it’s not the distribution maintainers who need to hear the message I laid out last time, but rather the team responsible for application deployment. Sometimes this is the application development team itself, or sometimes it’s a dedicated operations team. While the same thought process has made both bugs worse than they should be, I think the same underlying mistakes have been made, and that the current crop of blogs covering regreSSHion are asking the wrong questions (and thus missing the “bigger picture”) about this issue.
Like you, I subscribe to AppSec newsletters, blog feeds, and such. And, like you, I woke up yesterday to see a dozen message in my inbox about regreSSHion. After reading Qualys’ research, my first thought was “wow, this is crazy” and my second thought was “wow, SecOps teams are gonna have their hands full today.”
“You can’t have bugs in code you don’t have”
It was at this point that I realized most of these blogs and alerts were from AppSec companies. That struck me as odd for this sort of bug, but I suppose not entirely unexpected (it would have made total sense had these alerts come from operations security companies). I started to wonder “which customer of theirs has OpenSSH installed in their application container?” (and if so, why?)
Sure, regreSSHion is bad. But how can your application be exposed to this issue if you didn’t have OpenSSH installed in your container in the first place? One of the things I like to tell our own developers is “you can’t have bugs in code you don’t have”; in other words, strive for a thin environment where you have strict control over the landmines left around next to your application’s code. Were their customers potentially exposed because they simply based their application upon a fat base image and didn’t bother to take the time to clean things up? And once in this situation, how would their customers even know how widespread the issue was in their environment? These questions can be answered via the concept of reachability.
Runtime Reachability: “Is this piece of code used?”
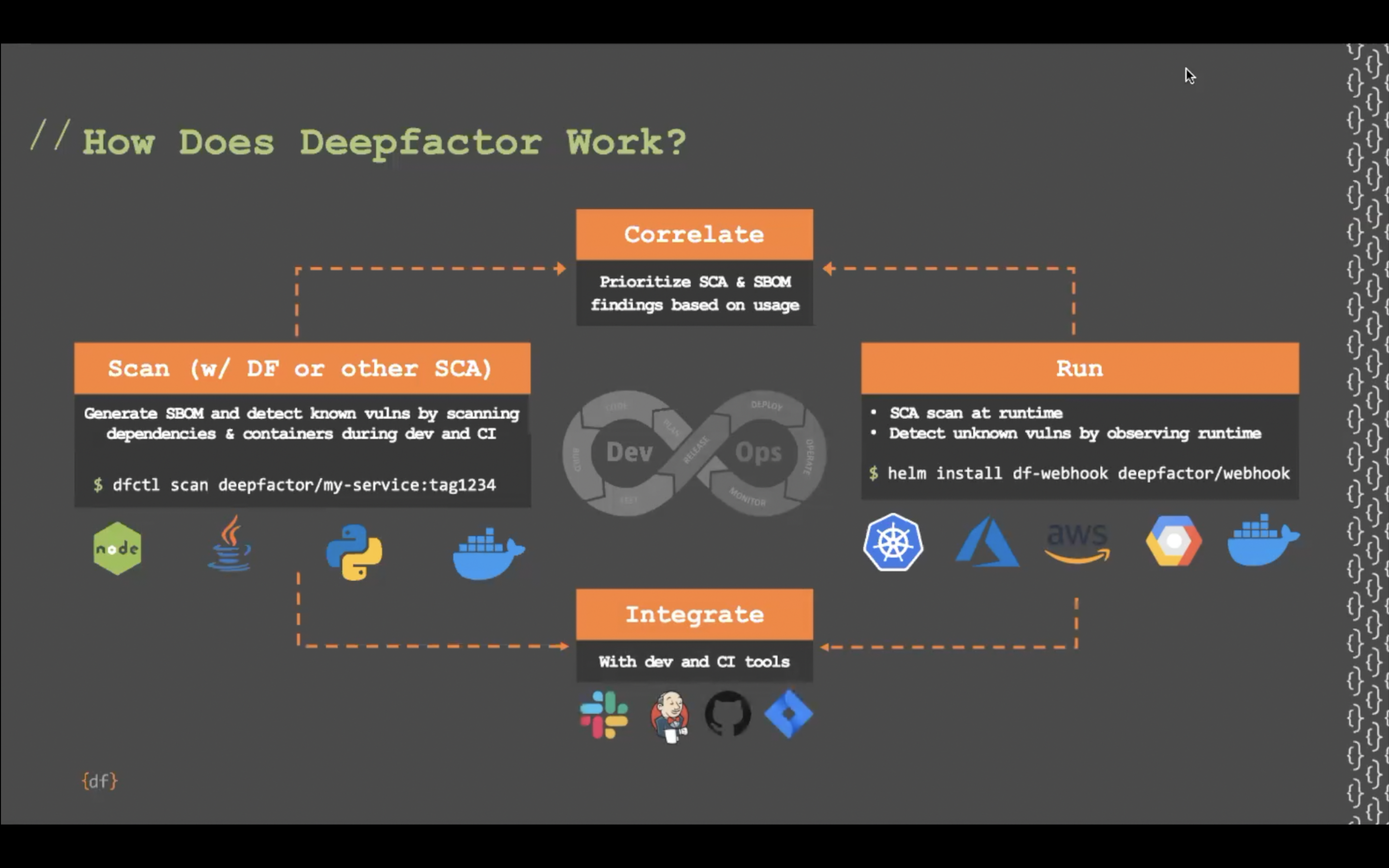
Let’s pause for a moment and talk about the concept of reachability as it applies to AppSec. Code reachability is a way to answer the question “is this piece of code used?” At Deepfactor, we answer this question by monitoring the application and reporting back what code was actually called and what code was not—e.g. what processes were launched, what libraries were loaded into memory and executed, and so on. Armed with this information, we can tell you what modules or packages in your container aren’t required; hopefully it is obvious that if something isn’t ever used, then it’s not required to be present and is a candidate for removal.
Importance of SCA Prioritization
As soon as regreSSHion was announced, Deepfactor customers immediately knew if they needed to prioritize patching based on this gathering of runtime usage correlation. In fact, our customers already knew if they had unused OpenSSH in their application containers and likely had already removed it ages ago. And for those customers who chose to leave it installed (possibly because the application legitimately needed it), our SCA (software composition analysis) artifact composition dashboard showed them exactly which container image(s) they needed to patch (sample Deepfactor SCA dashboard below). No guesswork involved.
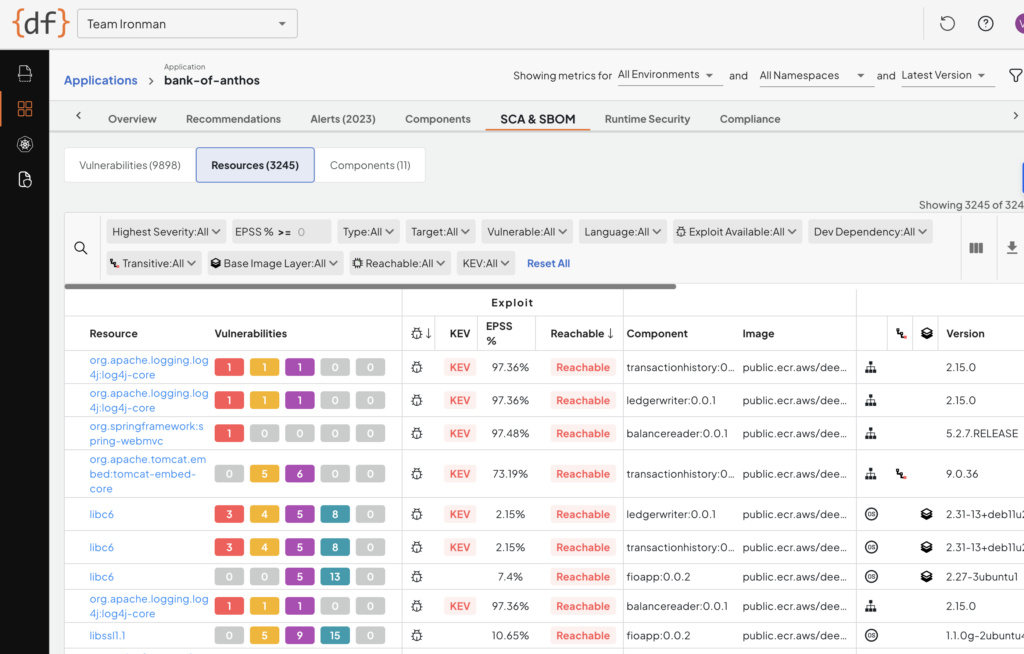
At this point some naysayers might be saying. “But Mike, even if I have OpenSSH installed in my container and can’t remove it, that’s ok since my containers can’t be accessed via ssh since I have a firewall.” You may not realize that this bug is both an RCE (Remote Code Execution) and an LPE (Local Privilege Escalation) since you can easily ssh to yourself (ssh to localhost). If an attacker gains a foothold in your non-root application and then uses this as a vehicle to launch a regreSSHion attack against the (normally unused) OpenSSH installed alongside the application, you’re still vulnerable to a root privilege escalation.
There are some possibly legitimate reasons OpenSSH could be installed alongside your application. For example, if your organization hasn’t yet moved to containerized deployment and you’re still using monolithic applications installed in VMs, then sure, you will likely need a way to login to those VMs, and OpenSSH is the obvious choice. This is why I said at the start of this article that patching is still critical. In this case, you’ll still need a way to ascertain what environments have this characteristic, and a good SCA tool (like what Deepfactor provides) is extremely useful here.
The Right Question(s) to Ask
The title of this article implies that we (as a general AppSec community) are asking the wrong questions when bugs like this are revealed. I think the most important question here isn’t what the other blogs are asking. The question isn’t “how can I patch, and how should I do it?.” If we ask that question today and don’t learn why we were asking it in the first place, we’re going to be asking it again and again in the future. The question(s) really should be “why should I even need to patch this if I’m not using it?,” or better yet, “how can I make sure that the next regreSSHion doesn’t affect me?”
To answer these questions, you need to understand the composition of your application (SCA) and, more importantly, what things your application is actually using as it runs. Then you immediately know what you’re vulnerable to, and almost as importantly, what you can safely remove from your environment to prevent being vulnerable to the next exploit. At Deepfactor, we provide these insights and this knowledge.
If you’d like to learn more about how Deepfactor can help in situations like this, contact us to connect with our team.

Free Trial Signup
The Deepfactor Application Security platform trial includes the full functionality of the platform, hosted in a multi-tenant environment.
Sign Up Today! >